Al realizar la solución de problemas básicos del sistema, es importante tener una vista completa de cada métrica en el sistema: la CPU, la memoria y, lo más importante, una gran visión del uso de E/S de disco.
En nuestro tutorial anterior, creamos un panel de control completo de Grafana para monitorear los usos de la CPU y la memoria.
En este tutorial, vamos a construir otro panel de control que monitoreará el uso de E/S de disco en nuestro sistema Linux, así como el uso de sistemas de archivos e inodos.
Vamos a usar Prometheus para rastrear esas métricas, pero veremos que no es la única forma de hacerlo en un sistema Linux.
Este tutorial se divide en tres partes, cada una proporcionando un paso hacia una comprensión completa de nuestro tema.
- Primero, veremos cómo se puede hacer el monitoreo de E/S de disco en un sistema Linux, desde el propio sistema de archivos (¡sí, las métricas están nativamente en su máquina!) o desde herramientas externas como iotop o iostat;
- Luego, veremos cómo Prometheus puede ayudarnos a monitorear nuestro uso de disco con el Exportador de Nodos. Vamos a configurar las herramientas, configurarlas como servicios y ejecutarlas;
- Finalmente, vamos a configurar un panel de control rápido de Grafana para monitorear las métricas que recopilamos anteriormente.
Listos?
Lección 1 – Fundamentos de E/S de disco
(Si solo viniste por Prometheus y el Exportador de Nodos, dirígete a la siguiente sección)
En los sistemas Linux, las métricas de E/S de disco se pueden monitorear leyendo algunos archivos en su sistema de archivos.
¿Recuerdas el viejo dicho: “En Linux, todo es un archivo”?
¡Bueno, no podría ser más cierto!
Si sus discos o procesos son archivos, hay archivos que almacenan las métricas asociadas en un momento dado.
Un recorrido completo por procfs
Como ya sabe, los sistemas de archivos de Linux están organizados desde un punto de raíz (también llamado “raíz”), cada uno de los cuales genera varios directorios que cumplen un propósito muy diferente para un sistema.
Uno de ellos es /proc, también llamado procfs. Es un sistema de archivos virtual creado sobre la marcha por su sistema, que almacena archivos relacionados con todos los procesos que se están ejecutando en su instancia.
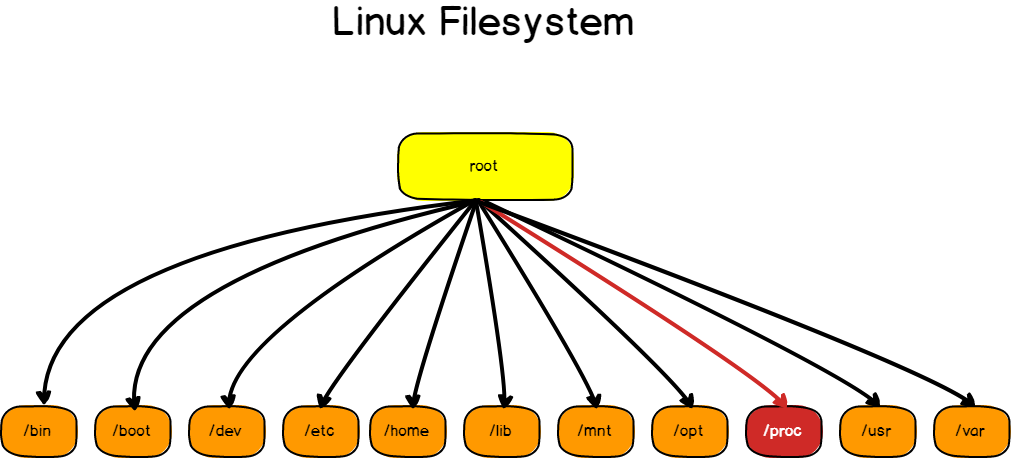
El procfs puede proporcionar información general sobre la CPU, la memoria y el disco a través de varios archivos ubicados directamente en /proc:
- cpuinfo: proporciona información general sobre la CPU, como las características técnicas del hardware de la CPU actual;
- meminfo: proporciona información en tiempo real sobre la utilización actual de la memoria en su sistema;
- stat: recopila métricas en tiempo real sobre el uso de la CPU, lo cual es una extensión de lo que cpuinfo ya puede proporcionar.
- /{pid}/io: agrega el uso de E / S en tiempo real para un proceso dado en su sistema. Esto es muy útil cuando desea monitorear ciertos procesos en su sistema y cómo se comportan con el tiempo.
> sudo cat /proc/cpuinfo
dev@dev-ubuntu:/proc$ sudo cat cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 79
model name : Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHzComo habrá adivinado, Linux ya expone un conjunto de métricas integradas para que tenga una idea de lo que está sucediendo en su sistema.
Pero inspeccionar archivos directamente no es muy práctico. Es por eso que tendremos un recorrido por las diferentes herramientas interactivas que cada administrador de sistemas puede usar para monitorear el rendimiento rápidamente.
5 Utilidades interactivas de la línea de comandos para E/S de disco.
En la práctica, un administrador de sistemas rara vez inspecciona archivos en el sistema de archivos proc, utiliza un conjunto de utilidades de línea de comandos que fueron diseñadas para este propósito.
Aquí hay una lista de las herramientas más populares utilizadas hasta el día de hoy:
iotop
iotop es una utilidad interactiva de línea de comandos que proporciona comentarios en tiempo real sobre el uso general del disco en su sistema. No está incluido de manera predeterminada en los sistemas Linux, pero hay recursos fáciles de seguir para obtenerlo para su sistema operativo: https://lintut.com/install-iotop-on-linux/
Para probarlo y verlo en vivo, puede ejecutar el siguiente comando:
# > sudo iotop -Po
# > sudo iotop -Po --iter 4 >> /var/log/iotop Ahora debería ver una vista interactiva de todos los procesos (-P) que están consumiendo recursos de E/S en su sistema (-o).
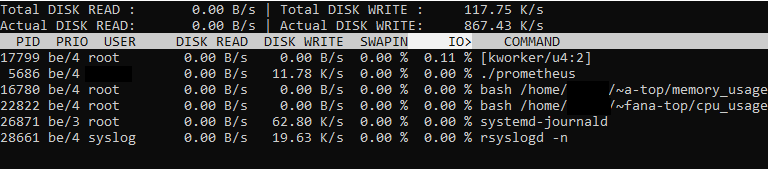
Los resultados son bastante autoexplicativos: proporcionan el utilización de lectura de disco, el uso de escritura de disco, la memoria de intercambio utilizada, así como la E/S actual empleada.
Una palabra para concluir
En este tutorial, aprendiste que puedes monitorear fácilmente la E/S de disco.
Monitorear estas métricas es esencial para cada administrador de sistemas que desee obtener pistas concretas de los cuellos de botella del servidor.
Ahora eres capaz de decir si provienen de latencias de lectura, latencias de escritura o un sistema de archivos que se está quedando sin espacio.
Con la E/S de disco, solo hemos rascado la superficie de lo que el exportador de nodos puede hacer, hay muchas más opciones y deberías explorarlas.
Espero que hayas aprendido algo nuevo hoy.
Hasta entonces, diviértete, como siempre.